Blue Intelligence - Serverless Natural-Language Oceanographic Analysis
The first prototype downloaded a 1% diverse sample of each region to avoid data costs. It was skewed, inaccurate, and slow. In the second version, I figured out it wasn't that complicated. I spun up a VM on the cloud and used AWS and Google's fast data connections to download all 4+ million Argo profiles, converted them to sharded Parquet files, and hosted a data lake on S3. That saved a lot of time and effort going forward. Separately, while working on the AIMO challenge, I learned how to make smaller LLMs obedient through orchestration and TIR (Tool Integrated Reasoning), which directly shaped how I built the agentic pipeline here.
How to build deterministic pipelines around non-deterministic AI outputs and make LLMs obedient. AST validation and topological sort for dependency resolution are the core techniques for secure LLM orchestration at scale. The S3 data lake plus DuckDB pattern works for any analytical domain with zero idle compute costs.
Built a fully serverless platform that translates plain-English oceanographic queries into interactive dashboards. An LLM orchestrates data retrieval from S3 Parquet shards via DuckDB, computes 27 complex thermodynamic metrics, and safely executes AI-generated analysis code in a custom AST-validated sandbox.
Blue Intelligence - live dashboard
§1. The Domain & The Problem
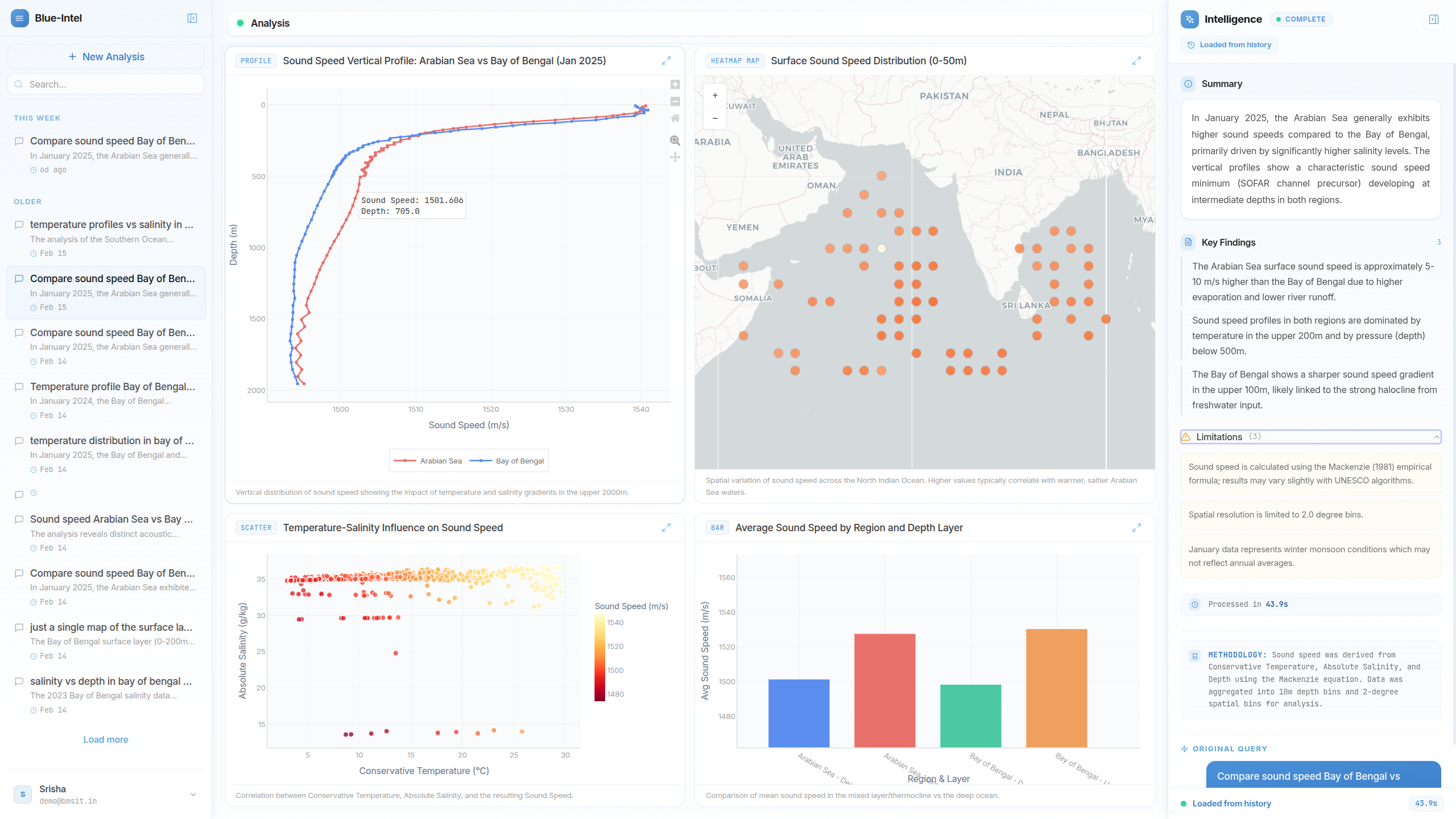
Oceanographers rely on the global Argo program, which generates millions of data profiles (salinity, temperature, pressure) across the world's oceans.
To answer something like "What was the temperature profile in the Arabian Sea in 2022?", a researcher typically downloads massive NetCDF files, writes complex data engineering scripts, and manually computes derived metrics using TEOS-10 thermodynamics. The goal was to make that a plain-English query.
§2. The Mental Model & Trade-offs
Storing millions of ocean profiles in an always-on relational database is cost-prohibitive and slow for large analytical aggregations.
DB Approach: Bypassed traditional databases entirely. Data is stored as Parquet shards in an S3 data lake and DuckDB executes SQL directly over HTTPS. Analytical database speeds with zero idle compute costs.
LLM Execution Problem: Piping LLM-generated Python directly into exec() is a massive security vulnerability.
Sandbox: A secure execution sandbox using Python's ast module validates the LLM's code before running it, blocks dangerous built-ins (eval, __import__) and system modules (os, sys, subprocess), then runs safe code in an isolated subprocess with strict timeouts.
§3. The Architecture
The backend runs on a 3 GB AWS Lambda and executes a strict 5-phase pipeline for every query:
- Plan: Gemini Flash decomposes the natural language input into a structured JSON plan (bounding boxes, time windows, depth ranges).
- Retrieve: DuckDB constructs and runs queries against the S3 Parquet shards.
- Compute: A topological sort resolves the dependency graph to compute 27 derived ocean metrics (Brunt-Vaisala frequency, sonic layer depth).
- Normalize: Profiles are converted into a normalized pandas matrix.
- Analyze: Gemini generates Python analysis code, executed in the AST-validated sandbox, returning structured JSON to the React frontend.